1. Migration Scenarios
Over the past years I’ve done several Oracle database migrations to a different platform (e.g. HP/UX to Linux) to a different edition (e.g. Enterprise Edition to Standard Edition) or to Unicode. The most easiest one nowadays is the platform migration as Oracle offers some nice features like cross platform transportable tablespaces or RMAN cross platform backups or if you want to migrate from Windows to Linux vice versa you can simply setup a data guard environment. Of course there are still some pitfalls like the downtime but in general it’s straight forward and well tested.
If you migrate from Enterprise Edition to Standard Edition there is currently no other way than to offload the old database and load the data into the new database using data pump or the good old export import. Again not very complex as long as there are no other changes you want to make (e.g. changing the character set). But the migration takes much longer than with RMAN or Transportable Tablespaces so you might look for a tool to minimize downtimes.
1.1 Minimum Downtime Migration
Sometimes companies claim that they can do live migrations or zero downtime migration. I’m pessimistic about this statement because over the last more than 10 years since I’m doing minimum downtime migrations I’ve only seen one successful live migration! The reason that you probably have a downtime is due to the fact that some additional changes have to be made to the environment (like network, TNS alias, the application or webservers) and that it might take some time before the source and target databases are in sync. That’s the reason why I’m always talking about minimal downtime and not zero downtime and it will offload a lot of risky tasks if you can afford having an application downtime for 10 to 30 minutes only.
Having this in mind it’s not very difficult to migrate from Enterprise Edition to Standard Edition or changing platform as a replication solution might work even better as cross platform transportable tablespaces or RMAN backups.
1.2 What about Unicode Migration?
Isn’t it similar to a migration from Enterprise Edition to Standard Edition? Oracle even allows you to change the character set of the database without copying any data using the old mechanism of csscan and csalter or the far better one named DMU (Data Migration Assistant for Unicode). DMU is a free graphical tool Oracle offers to scan the database looking for the used data types, the length of CHAR, VARCHAR2, NVARCHAR2 data fields and does a good job also checking for “dirty” characters. But at the end it tries to migrate the database in place to the new character set and that’s error-prone and has a high risk for a downtime longer than expected. That’s the reason why the Unicode Migration is similar to a migration from Enterprise Edition to Standard Edition with the exception that there is more work to do.
2. My Principles for Database Migrations
- Do not touch the production system as long as you can. Building up a new system allows a complete QA test on the production data.
- Prepare everything on the new system before the application needs to switch over.
- Test the new database with different applications and with some standard tools like Toad. This allows you to hopefully detect any “dirty” characters.
- Minimize the downtime for the production. Even if you have a downtime window of 24 or even 48 hours (like an ordinary weekend) and the pure migration takes about 12 hours. Keep in mind that there is a risk for an error like data corruption which leads in a complete database restore. Have you taken that time into account for your downtime and you are back at “Start” so you need to find another maintenance window for the next try.
Due to those principles I recommend using a replication solution like DELL SharePlex for Oracle or Dbvisit Replicat to migrate a database no matter if to a different platform, a different edition or to Unicode. You might ask for the costs but keep in mind my 4th principle: What are the costs for two Oracle DBAs working an entire weekend and do to some not foreseen circumstances failing in migrating the database? In most cases that’s far more expensive as the price for the additional software – and one replication expert. And have in mind that you now have an environment to test and the ability to use the replication even after you switched to the new database as a fallback option.
2.1 Pitfalls for a Unicode Migration
There are two very common problems when migrating to Unicode:
- The “wrong” data type definition
- The “hard” limits of the Oracle database
Is this a valid statement?
CREATE TABLE kunden ( kundid NUMBER(10) GENERATED BY DEFAULT AS IDENTITY, anrede VARCHAR2(5), vorname VARCHAR2(20), nachname VARCHAR2(20), geburtstag DATE);
Yes and No: Yes the statement is valid. Oracle will not complain and the table will be created anyway. You can add your records to it as long as each column fits into the maximum defined length. But what about this:
SQL> INSERT INTO kunden (anrede, vorname, nachname)
VALUES ('Herr','Mike','Mülleimeraussteller');
It fails with the following error message:
VALUES ('Herr','Mike','Mülleimeraussteller')
*
ERROR at line 2:
ORA-12899: value too large for column "DEMO"."KUNDEN"."NACHNAME" (actual: 21, maximum: 20)
But the definition says 20 characters and the surname has exactly 20 characters. The reason is that these German special characters have a two byte representation in a Unicode character set so the total length of the column is 20 bytes and not 20 characters. Answering the question: “No” the statement is not valid because you probably expected that the length of the field is 20 characters and not 20 bytes. To make this a valid statement in both aspects you should change it to:
CREATE TABLE kunden ( kundid NUMBER(10) GENERATED BY DEFAULT AS IDENTITY, anrede VARCHAR2(5 CHAR), vorname VARCHAR2(20 CHAR), nachname VARCHAR2(20 CHAR), geburtstag DATE);
Now the insert is successful:
SQL> INSERT INTO kunden (anrede, vorname, nachname)
2 VALUES ('Herr','Mike','Mülleimeraussteller');
1 row created.
How does this influence the Unicode migration? Most of the time you or the application developer did not take a multi byte character set into account so all CHAR and VARCHAR2 are probably created with a byte length semantic and not char length semantic. If you use Oracle data pump or the old export / import procedure it is not possible to change the source semantic. The only chance is to “pre-create” the target tables and only import the data. Toad can easily assist as there is the option not to generate the length semantics while generating a schema script: Uncheck “Include Byte/Char spec when creating DDL scripts from 9i databases”.
Before running that script on the target you can simply change the length semantic to CHAR and all tables will be created with the correct definition.
ALTER SESSION SET NLS_LENGTH_SEMANTICS='CHAR'; -- -- Create Schema Script -- Database Version : 11.2.0.3.5 ...
Please set length semantics for a session only, because even though in theory Oracle allows to set the length semantics to CHAR for the entire database this can cause problems with patches and upgrades as this implies to data dictionary objects as well.
But there is a second problem: the “hard” limit of the Oracle database. Let’s assume you’ve defined a description field with VARCHAR2(4000 CHAR).
ALTER TABLE customers ADD DESCRIPTION VARCHAR2(4000 CHAR);
So how many characters can be stored in that field? 4000! … if you have one byte characters. The “hard” limit for VARCHAR2 is 4000 BYTE until Oracle 12c. So if you hit that limit there was no other way as to use CLOB instead of VARCHAR2 – but that has other implications so be careful!
2.2 VARCHAR2(32k) in Oracle 12c
With Oracle 12c it sounds like you can simply create the table with VARCHAR2(4000 CHAR) and you should be able to insert also multi-byte characters. But that’s only partly true: Per default even Oracle 12c only supports VARCHAR2 up to 4000 BYTE. The behavior can only be changed if you upgrade(!) the database in the following way:
SQL> SHUTDOWN IMMEDIATE SQL> STARTUP UPGRADE SQL> ALTER DATABASE OPEN MIGRATE; -- Only the Pluggable Database SQL> ALTER SYSTEM SET MAX_STRING_SIZE=EXTENDED; SQL> @?/rdbms/admin/utl32k.sql
Now your database is capable of handling VARCHAR2 data type with a length of maximum 32768 BYTE!
You don’t have to change your table definition but now you can add the description with 4000 characters no matter if they are single- or multi-byte.
Behind the curtains Oracle automatically switches the VARCHAR2 field as soon as the number of bytes exceeds 4000 BYTE to BLOB with the same character set as VARCHAR2. You have to take into account that the size of the table (column BLOCKS in USER_TABLES) no longer includes the DESCRIPTION field and the space it occupies.
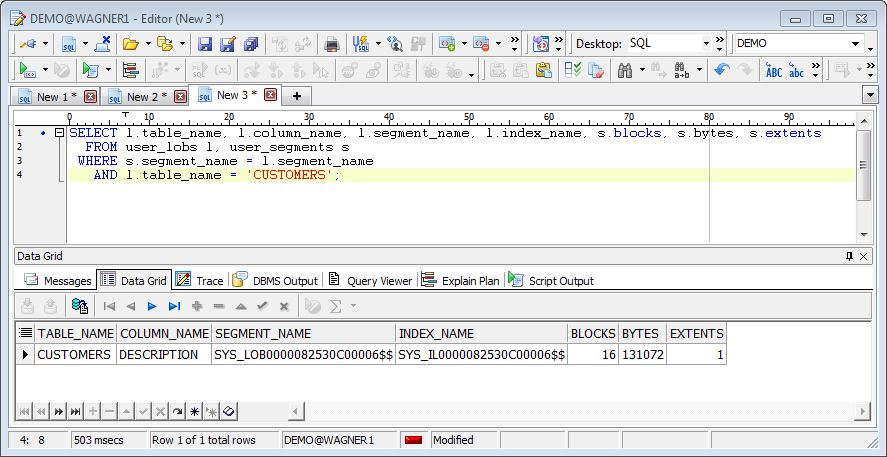
But at a glance this is a great step forward for an easier migration to Unicode.
2.3 What are “dirty” characters?
It sounds like an unusual behavior similar to a corruption but in fact it has been seen many times because many developers (and I’m sorry but they are guilty) do not know how character sets are properly used. Having in mind that the database character set is US7ASCII they assume that the client should work with the same character set because otherwise some translations have to occur which can cause problems (e.g. performance, missing characters, etc.). So they recommend to set the same character set for the client as for the database. Oracle has this nice environment variable named NLS_LANG and by setting NLS_LANG=GERMAN_GERMANY.US7ASCII you would assume that there it is not necessary to convert any characters from the client to the database as long as the database has the same character set – that’s true and Oracle*Net which is responsible for the translation actually does what you told him to do: “Don’t convert any character coding’s!”.
What’s wrong with it? Simply speaking: everything! Your client is probably not an old ASCII terminal but a MS-Windows PC or a Linux Server running a Java Application. In Europe MS-Windows is originally installed using WE8MSWIN1252 which is the Western European character set with nearly every character we need in Europe (even more as the corresponding ISO-Character set WE8ISO8859P15). Your Java Application is probably already a Unicode application and if you are using Toad again you do have a Unicode application in hand. But you told Oracle*Net not to do any character set conversions. Now the character code representation is 1:1 stored in the database regardless if that’s a valid code or not. As long as you are using the same setting for NLS_LANG to read the data everything looks fine and you assume that your settings are okay. But what if you change your application? What if your data was inserted using an application server and you query the data using Toad? Some awful cryptic data is shown instead of the nice sentence your originally wrote.
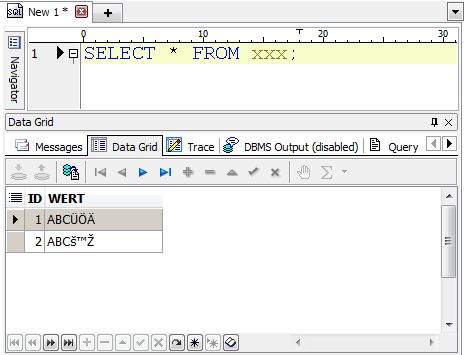
Now you might have a better idea how easy it is to have “dirty” characters in the database – and it’s of course difficult to clean up the data because you need to know the original character set of the client which inserted the data. I’ve recently migrated a database from US7ASCII to Unicode where the customer was using three different clients (UTF16, WE8ISO8859P1, WE8MSWIN1252) all inserting thousands of German sentences with “Umlauts” and the “€” symbol. We had to change the database character set (which is not officially supported) of the source or better interim database to extract the data in the correct format three times and were able to clean up most of the database. But it was a cumbersome job and I would appreciate that this doesn’t happen that often.
At the end the migration was successful and now the database is running with Unicode and the data can be queried regardless of the client.
3. Conclusion
Unicode migration is not an easy task and a tool like Database Migration Assistant for Unicode can only help partly. So before you start a migration check the following bullet points:
- Make it a project with a project manager
- Add some budget to it
- Have a timeline of at minimum three months
- Expect the unexpected
If you follow these rules I’m sure your migration will be successful, if not there is a good chance that you end up in a mess.




mark
Is this still relevant in versions >=12.2 now that we can plug in a PDB of any character set as long as the CDB is AL32UTF8 ?
For example, migration could be :
1) Migrate NON-CDB WE8ISO8859P1 to PDB in temporary CDB created with WE8ISO8859P1
2) Create target CDB with AL32UTF8
3) Unplug PDB created in step 1) and plug into CDB created in step 2)
In this way, complex and costly data character conversions are completely avoided.
Johannes Ahrends
Hi Mark
okay you can plug in a single byte PDB into a Unicode CDB. But that doesn’t help as the data in the PDB is still limited to WE8. You are unable to add special Eest European characters into that PDB.
Regards
Johannes