Wenn man nur das Wort „Reorganisation“ erwähnt, endet dies meist in einer heftigen Diskussion über die Vor- und Nachteile von Reorganisationen. Der Grund ist, dass Oracle im Laufe der Jahre die Architektur der Datenbank immer wieder angepasst hat und damit viele Gründe, die ursprünglich eine Reorganisation notwendig machten, nicht mehr existieren.
Historie
Die erste Version von Oracle, mit der ich direkt in Kontakt gekommen bin, war die Version 6. In dieser und auch noch in der Version 7 gab es die Limitierung der Anzahl von Extents. Es wäre müßig gewesen, über eine Reorganisation zu diskutieren, denn es gab eine maximale Anzahl von Extents, die eine Tabelle haben konnte. Diese variierte zwar je nach Blockgröße, aber da zu der Zeit die Standardblockgröße bei 2k (!) lag, war in den meisten Fällen bei 121 Extents Schluss. Wenn man dieser Grenze nahe kam musste man dringend das Segment reorganisieren. Mit der Version 7.3 wurde diese Grenze dann endlich aufgehoben und fortan ist es möglich, dass ein Segment eine unlimitierte Anzahl von Extents haben kann. Aber bedeutet dass auch, dass es keinen Grund mehr gab, ein Segment zu reorganisieren, wenn es eine bestimmte Anzahl von Extents überschritten hatte? Doch, denn das Extent Management wurde von zwei Data Dictionary Tabellen verwaltet: FET$ = Free Extent Table und UET$ = Used Extent Table. Diese beiden Tabellen konnten bei großer Last auf dem Server durchaus zu einem Engpass werden. Das bedeutet auch, je größer die einzelnen Extents waren, umso seltener mussten diese Tabellen geändert werden. Dies war zwar keine harte Grenze mehr aber dennoch ein Grund für eine Reorganisation.
Der nächste Grund – oder besser Mythos – für eine Reorganisation war und ist die Fragmentierung einer Tabelle. In den 90er Jahren war eine „Große Datenbank“ ein paar GByte groß und ein einzelnes Objekt ein hatte einige hundert KByte oder ein paar MByte. Aus Performance-Gesichtpunkten war es optimal, für das Lesen von Daten(z.B. bei einem Table Scan) möglichst wenig I/Os auszuführen – und das ist natürlich auch heute noch so. Die Extents sollten dafür sorgen, dass möglichst viele Daten „am Stück“, d.h. mit einem I/O gelesen werden konnten, also ein „Scattered Read“ vermieden wurde.
Und was war mit der Wiederverwendung von Platz? Festplatten waren teuer und daher war es wichtig, nach dem Löschen von Daten diesen Platz wieder freizugeben. Dem stand jedoch der Overhead für die Verwaltung von Blöcken gegenüber (Freelists). Um den Verwaltungsaufwand gering zu halten gab es zwei Parameter: PCTREE, der angab (und immer noch angibt), wie viel Platz in einem Block für Änderungen freibleiben soll und PCTUSED, der angab, wann ein Block wieder als „Frei“ markiert werden sollte, d.h. also wann wieder Datensätze eingefügt werden durften. Viele Oracle Kunden beschwerten sich zu der Zeit, dass, nachdem sie Daten archiviert hatten und dem entsprechend viele Sätze aus den „großen“ Tabellen gelöscht hätten, der Platz für die Tabelle trotzdem nicht kleiner wurde, im Gegenteil, nachdem neue Sätze eingefügt wurden, wuchs die Tabelle sogar noch. In diesem Fall konnte man ebenfalls nur dazu raten, nach einer Archivierung von Daten (und dem anschließenden Löschen) die Tabelle bzw. besser Tabellen zu reorganisieren.
Aber gelten diese Argumente auch heute noch?
Durch die Einführung von Locally Managed Tablespaces in Version 8i gehören die Tabellen FET$ und UET$ der Vergangenheit an, d.h. die Verwaltung von Extents spielt heute für die Performance keine Rolle. Und seit Oracle 9i gibt es das Automatic Segment Space Management (ASSM) und damit wird der freie Platz in den Blöcken durch eine Bitmap Struktur verwaltet, Freelists werden nicht mehr benötigt, PCTUSED gibt es nicht mehr und trotzdem werden die Blöcke nach Löschoperationen gleichmäßig wieder aufgefüllt.
Wenn wir außerdem heute über „Große Datenbanken“ reden, dann sind diese in der Regel einige TByte groß, selbst die SGA kann schon mal größer als ein TByte sein und unser SAN Storage hat auch noch ein paar TByte an Hauptspeicher. Daraus folgt, dass man sich über die Größe von Extents wirklich keine Gedanken mehr zu machen braucht, solange ein Extent mindestens 1 MByte groß ist, weil dies für viele Server einem I/O entspricht. D.h. solange das Extent ein Vielfaches der Größe eines I/Os ist, spielt die Anzahl von Extents keine Rolle. Meiner Ansicht nach gibt es Extents heute nur noch aus Kompatibilitätsgründen und wären eigentlich überflüssig.
Gibt es also keinen Grund mehr für Reorganisationen?
Doch es gibt sie! Es gibt einen Objekttypen, der sich in all den Jahren kaum verändert hat: B*Tree Indizes!
Der „normale“ B*Tree Index ist immer noch ein wichtiger Kandidat für eine Reorganisation. Speziell nach einer Archivierung. Der Grund ist, dass ein Index ausschließlich wächst und nicht automatisch kleiner wird, wenn die „Leaf“-Blocks leer sind. Das kann ein ziemliches Performance-Problem bei Primärschlüsseln oder indizierten Datumsfeldern sein, da neue Sätze „rechts“ eingefügt werden und alte Sätze „links“ gelöscht. Aber auch andere Indizes können Kandidaten für eine Reorganisation sein.
Das folgende Beispiel stammt aus einem aktuellen Projekt:
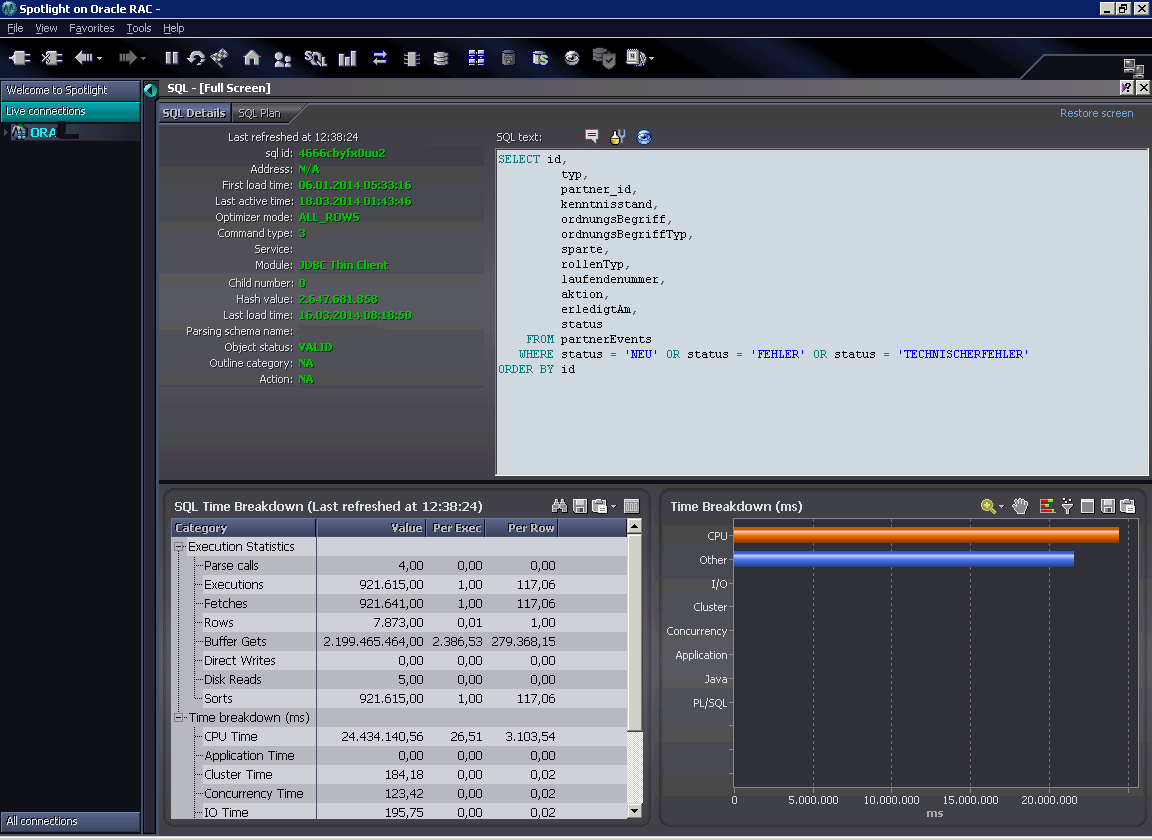
Das erste Bild zeit eine Abfrage auf eine Tabelle, die einen Index auf der Spalte „Status“ hat. Diese Abfrage wird extrem oft aufgerufen und in den meisten Fällen wird kein Datensatz zurückgeliefert, da keiner den Status „NEU“, „FEHLER“ oder „TECHNISCHER FEHLER“ hat.
Wenn man sich die Zahlen im Spotlight ansieht, dann stellt man fest, dass je Ausführung 2400 Blöcke (d.h. ca 19MByte) gelesen werden, obwohl nicht einmal 1 Prozent der Fetches einen Datensatz zurückliefert. Wie zu sehen beträgt die Ausführungszeit ca. 50 Millisekunden, scheint also sehr schnell und man ist gewillt, nicht weiter darüber nachzudenken. Allerdings ist liegt die Anzahl Ausführungen bei fast einer Million, d.h. mehr als 13 Stunden.
Also schauen wir uns die Abfrage doch einmal näher an: Wie auf dem zweiten Bild zu sehen, wird der Index auf der Spalte Status genutzt.
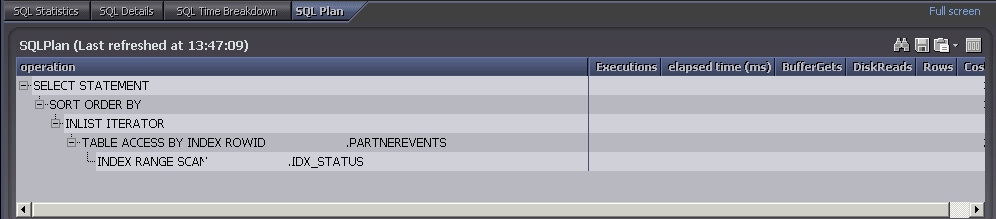
Aber warum werden dann jedes Mal 2400 Blöcke gelesen, der Zugriff auf den Index müsste doch sofort erkennen lassen, dass es keinen Satz gibt.
Die Antwort ist: aus der Tabelle wurden vor nicht allzu langer Zeit einige Millionen Datensätze gelöscht und natürlich wurde der Index hinterher nicht reorganisiert.
In dem Projekt haben wir kurzerhand folgenden Befehl abgesetzt:
SQL> ALTER INDEX IDX_STATUS REBUILD ONLINE;
Die Ausführung dauerte nur wenige Sekunden und das Ergebnis war, dass die Anzahl gelesener Blöcke auf 2 (!) reduziert wurde und die Ausführungszeit nicht mehr messbar war.
Zusammenfassung:
Ich möchte an dieser Stelle nicht behaupten, dass die Reorganisation einer Tabelle nicht notwendig ist. Oft erzählen mir meine Kunden, dass nach einer Tabellenreorganisation die Abfragen viel schneller waren – allerdings vergessen sie dabei, dass bei einer Tabellenreorganisation natürlich auch automatisch alle Indizes reorganisiert werden. Und natürlich wird auch der Buffer Cache besser ausgenutzt, wenn eine Tabelle durch eine Reorganisation wieder „zusammengepackt“ wird. Aber in vielen Fällen führt eine Indexreorganisation zu einem ähnlichen Ergebnis. Dabei sollte noch beachtet werden, dass diese weit bequemer und weniger kritisch ist, als die Reorganisation einer Tabelle.




Keine Kommentare zu “Datenbank Reorganisation”