Talking about reorganization very often end up into tough discussions about the pros and cons of reorganization. The reason is that over the past years Oracle changed the architecture of the database a lot and several aspects which have led into reorganizations do no longer exist.
History
Look at Oracle 6 and 7 where we had the limitation on the number of extents. This was a hard fact and nobody would have discussed that because the number of extents was simply limited corresponding to the block size. As at that time the default block size of a database was 2k (!) the maximum number of extents for a segment was 121 – period. No discussion just the fact that when you reach that number you have to reorganize the object. With Oracle Version 7.3 this limitation was lifted and you could have unlimited number of extents. But does that mean that there was no longer a need for reorganization because of the extents – not really. As the extent management was handled by two data dictionary tables (FET$ and UET$) which stands for free extent table and used extent table respectively those could become a bottleneck if there was a heavy load on the server. The larger the individual extents the less frequent those tables where updated. This was again a fact (but more weak) for reorganizations.
The next fact – or let me better say “myth” – for reorganization was the fragmentation of a table. In the later 90s we were still talking about a few GB in total size of a database so a single object will probably have some KB or MB on size – and size matters! From the performance perspective it was optimal if all the data needed (esp. for table scans) can be read with a minimum number of I/Os . And that’s true until nowadays. So the idea of extents at that time was that for larger tables the extent size should be not less than one I/O to avoid a scattered read.
But what about space allocation after some data has been removed? Disk capacity was expensive at those days so to free up some space for new data was important. But the Oracle concept was: do not reuse space in a block until the block has been emptied up to 40% (default). Many Oracle customers were complaining about the fact that they deleted a bunch of data out of their largest tables but the table size still increases – thanks to PCTUSED! Yes there was a need to reorganize objects after massive row deletions (data archiving).
But are those arguments still valid today?
From the architecture perspective FET$ and UET$ are long gone as Oracle introduced Locally Managed Tablespaces already with Oracle 8i and I haven’t heard any argument not to use LMTS for years now. And since Oracle 9i Automatic Segment Space Management is available which enables the management of the free space of the block within the segment. So no need for reorganizations after mass deletes!?
If we are talking about large databases today we are talking about several terabyte of data, the SGA memory sometimes even exceed a terabyte and another terabyte of memory sits on the SAN storage. So as a consequence there is not necessary to care about the size of a certain extent as long as it is at minimum 1 MB — for most systems as that is the size of one I/O. So from my perspective extents are no longer necessary and I guess they exist in the database just for compatibility reasons.
But does this mean that there is no need for reorganizations?
No at all. There is one object type which architecture hasn’t changed at all over the past 20 years: B*Tree Indexes!
The ordinary B*Tree index is still a candidate for reorganization especially if data is being removed from a table. The reason is that the index is always growing and not automatically shrinking if leaf blocks are being emptied. This has a very negative impact especially on primary keys and date columns, as new values are added to the right and old keys are removed from the left side of the leaf blocks. But any other index can be a candidate as well.
Here is a great example I encountered last week:
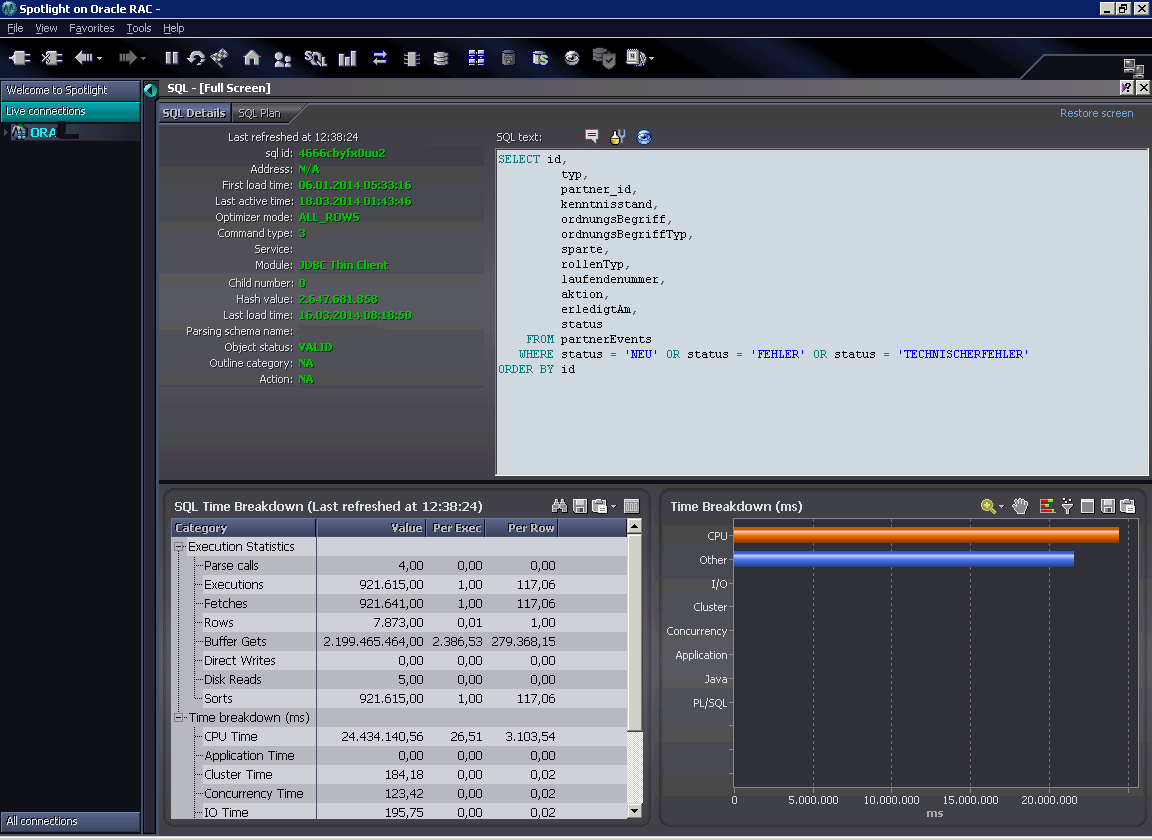
The first screenshot shows the query and there is an index on the column “status”. Normally there is not a single row having the status “NEU”, “FEHLER” or “TECHNISCHERFEHLER”. So the query will return “no rows selected”.
If you look at the figures in Spotlight you see that the query reads about 2400 blocks per execution even though not even 1 percent of the fetches brings back a row.
The elapsed time per query was about 50 milliseconds – which doesn’t sound very long but look at the number of executions -> nearly 1 million.
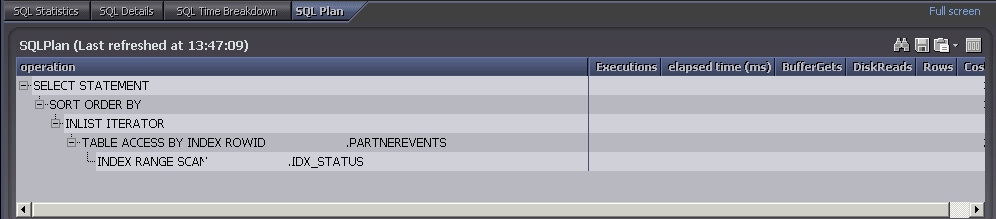
As you can see on the second screenshot the index on status is being used. So the question is: why does the query read 2400 blocks per execution if the index should tell him immediately that there is no row.
The answer is: in the past we deleted some millions of rows from that table and did not realize that we had to reorganize the index.
So we executed the following command (which took some few seconds):
SQL> ALTER INDEX IDX_STATUS REBUILD ONLINE;
And immediately the number of blocks per execution dropped to two (!) and the execution time was no longer measurable!
Conclusion:
That doesn’t mean the table reorganization isn’t necessary. Many times customers told me that after reorganizing the table the queries run much faster. That’s true because when you are reorganizing your tables you are going to reorganize your indexes as well. And to free up space in your database or under some circumstances table reorganization is useful but index reorganization is much easier less error prone and might have the same positive effect to your users.




No comments on “Database Reorganization”